


— Next episode of the /usr/bin/grep saga —
The incontournable logs aggregation Hortonworks, MapR and myDistrib ![]() 2.6.X has been continued #1@2015 (
2.6.X has been continued #1@2015 (![]() 2.7.1), #2@2016 (
2.7.1), #2@2016 (![]() 2.7.2), #2.1@2016.
2.7.2), #2.1@2016.

![]() &(ElasticSearch->grep) = &(*ElasticSearch.grep) ?
&(ElasticSearch->grep) = &(*ElasticSearch.grep) ?
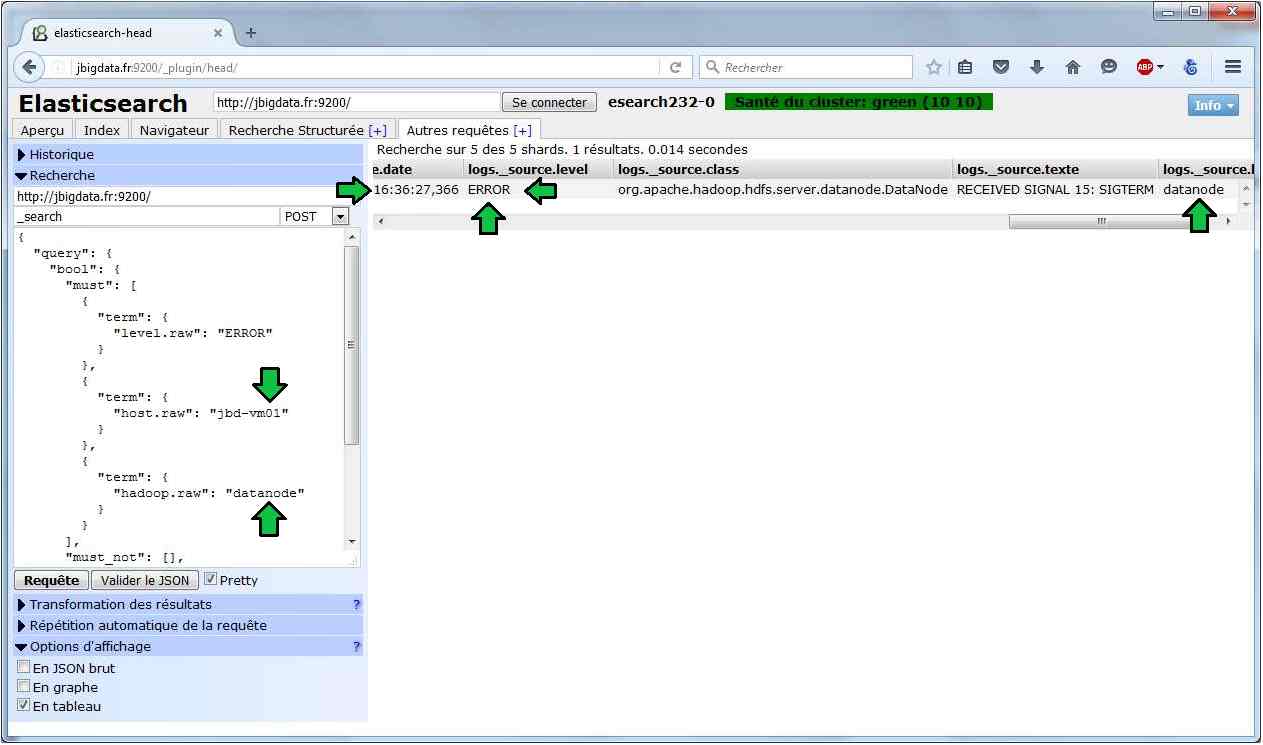
![]() Spark cluster ready.
Spark cluster ready.
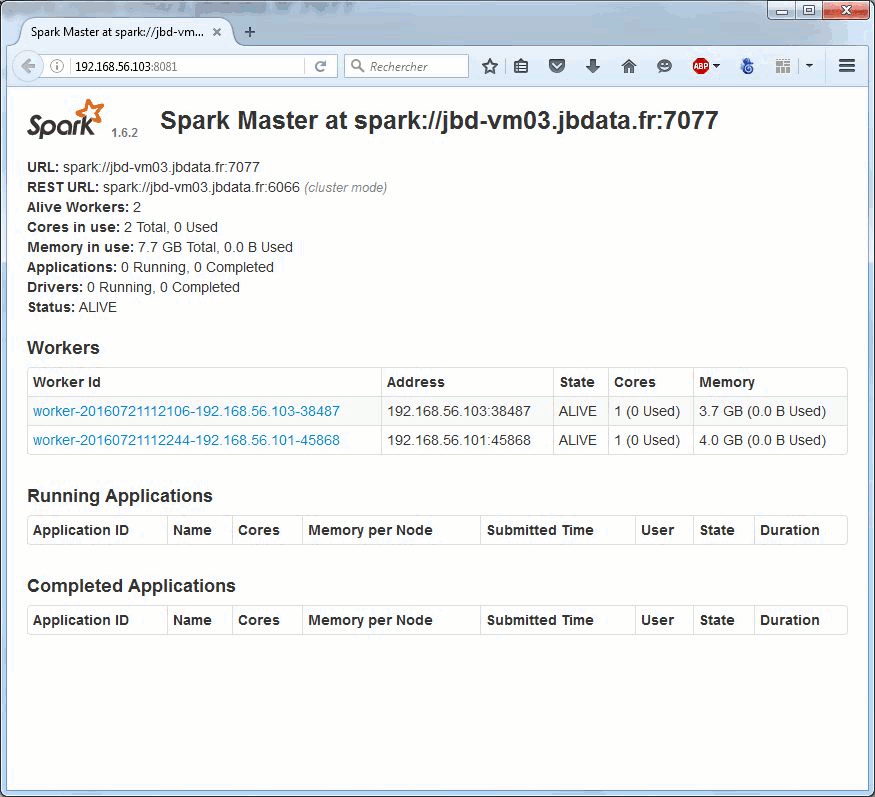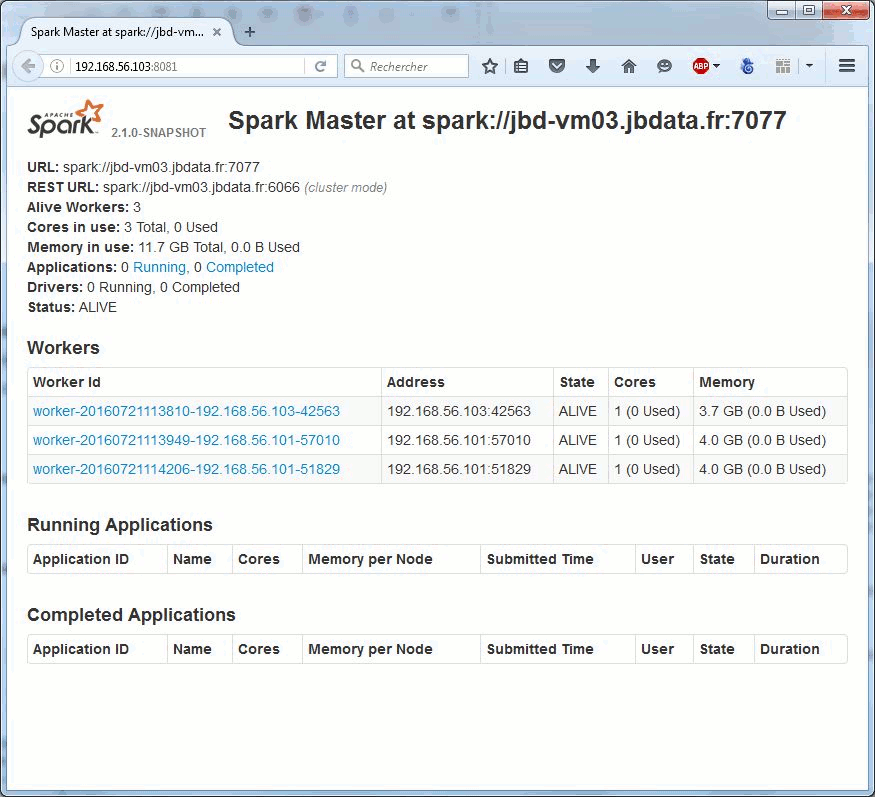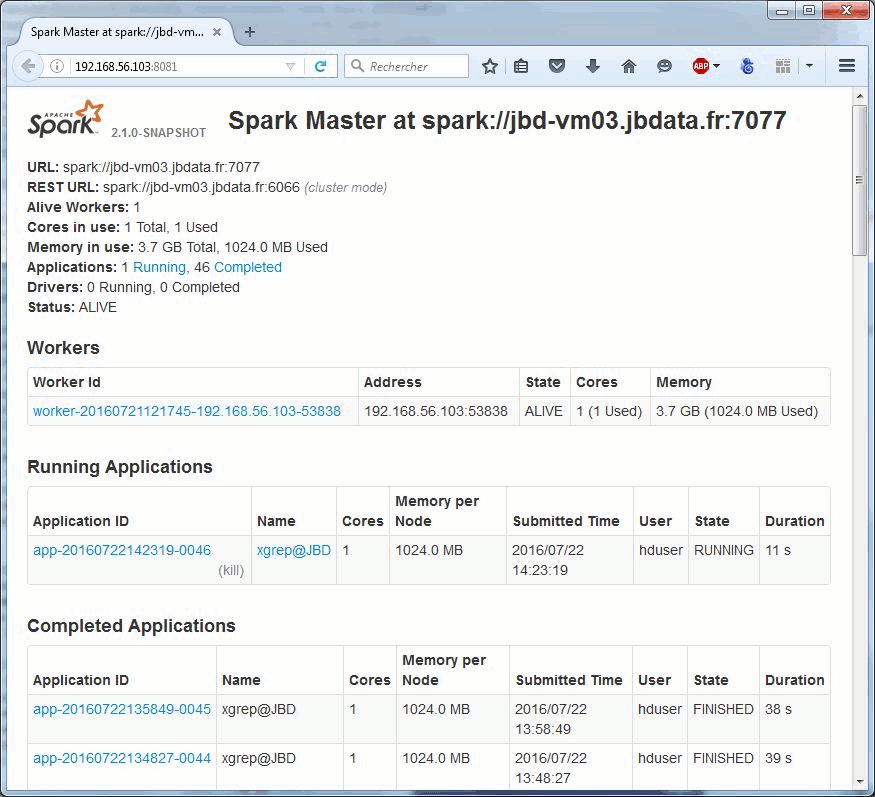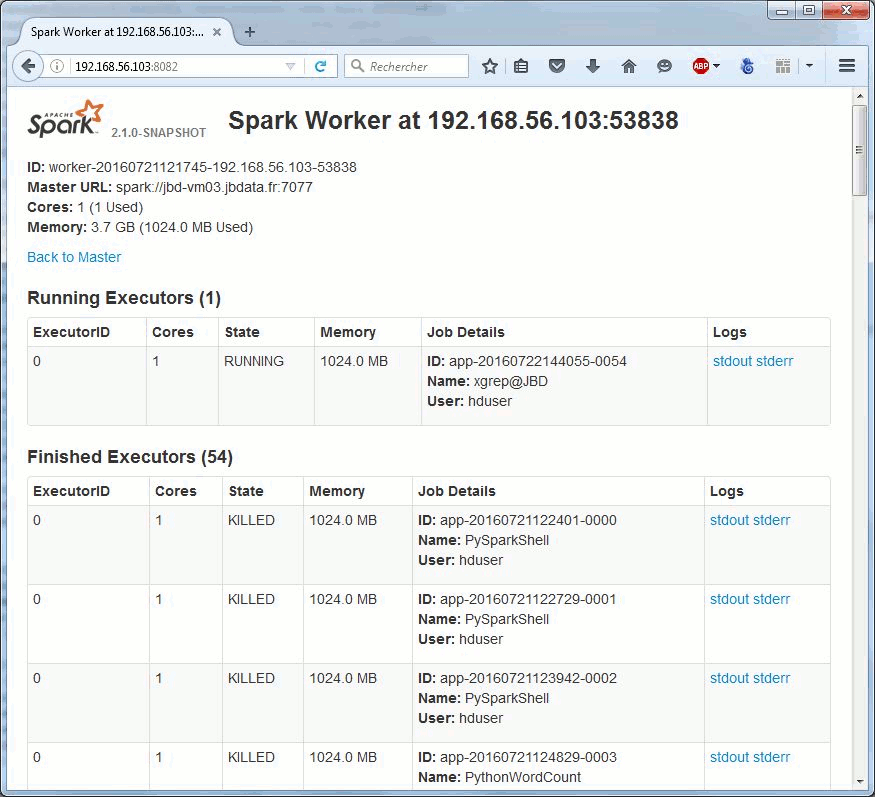
![]() From oldschool grep to org.apache.hadoop.examples.Grep (grep 2.0) to xgrep.py (grep 2.1).
From oldschool grep to org.apache.hadoop.examples.Grep (grep 2.0) to xgrep.py (grep 2.1).
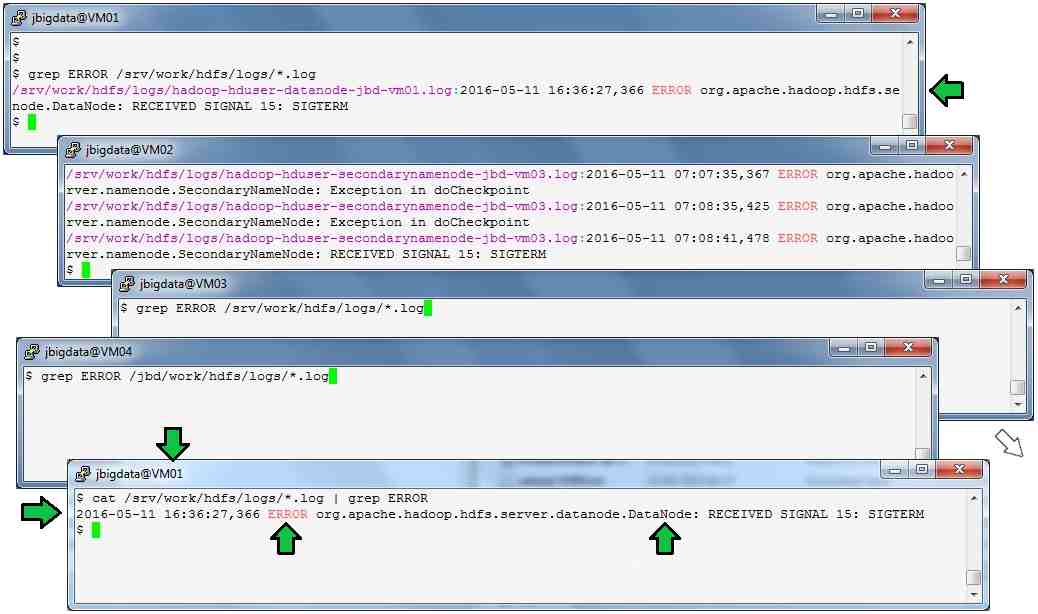
![]() MapReduce grep 2.0, already oldschool in the BigData timescale ?
MapReduce grep 2.0, already oldschool in the BigData timescale ?
hadoop org.apache.hadoop.examples.Grep hdfs://vm01.jbdata.fr:9000/logstash/2016-05-12 hdfs://vm01.jbdata.fr:9000/_output "INFO"
![]() Spark-Python grep 2.1, soon oldschool in the roadmap ?
Spark-Python grep 2.1, soon oldschool in the roadmap ?
/usr/local/spark/bin/spark-submit /data31tech/dev/spark-00/xgrep.py /test/lstash-00/2016-06-10/hadoop-hduser-datanode-vm01.log ERROR
#
# @author JBD-2016-07
# http://data31tech.fr
#
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.sql import SparkSession
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: xgrep file pattern", file=sys.stderr)
exit(-1)
aSparkContext = SparkContext(appName="xgrep@JBD")
aFile = aSparkContext.textFile(sys.argv[1])
theErrors = aFile.filter(lambda line, pattern=sys.argv[2] : pattern in line)
print("Results#SparkContext:")
print(theErrors)
print("Number of {} : {}".format(sys.argv[2], theErrors.count()))
# for anItems in theErrors.collect():
# print(anItems)
aSparkContext.stop()
![]() 2nd level, SparkSession release. 3rd level, RDD for another CaseStudy#*.
2nd level, SparkSession release. 3rd level, RDD for another CaseStudy#*.
#
# @author JBD-2016-07
# http://data31tech.fr
#
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.sql import SparkSession
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: xgrep file pattern", file=sys.stderr)
exit(-1)
aSparkSQLSession = SparkSession.builder.appName("xgrep@JBD").getOrCreate()
theLines = aSparkSQLSession.read.text(sys.argv[1])
theErrors = theLines.filter("value like '%ERROR%'")
print("Results#SparkSQLSession:")
print(theLines)
print(theErrors)
theLines.show()
theErrors.show()
aSparkSQLSession.stop()
![]() From ASM, C/C++, SDK32/MFC, JAVA, 2D/3D, PHP, Androïd, HTML5 to Pig Latin, jruby, python by the way Shell(s), PERL, IDL, OCCAM, LISP, PROLOG, APT, TODO#?
From ASM, C/C++, SDK32/MFC, JAVA, 2D/3D, PHP, Androïd, HTML5 to Pig Latin, jruby, python by the way Shell(s), PERL, IDL, OCCAM, LISP, PROLOG, APT, TODO#?
{kind=link}